|
|
除了之前章节提到的各类性能指标,用软件评估工具可以对各种AI芯片架构的性能做出早期的综合评价,以便指导架构的改进。比如麻省理工学院和英伟达的研究人员联合开发的评估工具Accelergy[Accelergy]和 Timeloop[Timeloop]。Accelergy是专门评估AI加速器功耗的工具,允许用户自定义如处理单元的数量、存储器容量、片上互联网络的连接数量及长度等参数,以对AI加速器进行架构级的功耗评估。Timeloop通过输入DNN模型和加速器硬件架构的参数,在一定的约束条件下,将模型映射到指令和架构上,再根据模型在加速器上运算执行的情况,给出性能,功耗和面积的评估,以此对不同的硬件架构之间进行比较。
但从系统的角度,对人工智能芯片在各种深度学习工作负载上的表现,用公认的合理指标进行综合的打分,才是给出公平性能评价的正道。这种方式就是基准测试。
说到基准测试,其实CPU,GPU等通用处理器在基准(Benchmark)上跑分已经有好几十年的历史了。著名的基准包括工业界老牌标准SPEC,为嵌入式芯片而定制的EEMBC和Coremark,过气却不死的Dhrystone以及为手机而生的安兔兔等等。随着近年来,人工智能及其专用芯片的崛起,为人工智能开发专用的基准成为了一门显学。如DeepBench,AIBench等各种基准层出不穷,但其中最有影响力的莫过于由大卫•帕特森(David Patterson)倡导的,由谷歌、英伟达 、哈佛大学、斯 坦 福大学等一众业界和学界顶尖机构发起的MLPerf(Machine Learning Performance)[MLPerf]。
于2018年公布第一版训练基准的MLPerf并不是单纯地衡量芯片的一些硬指标,比如硬件算力,或者软件栈的性能,而是综合衡量深度学习软件框架、AI 芯片以及平台的整体端到端的性能。针对不同的应用场景,目前MLPerf有六种细分的基准。训练基准分训练和训练 HPC两类,推理基准则包括Datacenter(数据中心),Edge(边缘侧),Mobile(移动设备)和Tiny(专注于嵌入式系统)四个分类。毕竟现在从云到端上各式各类的芯片都支持人工智能,如果放在同一个基准下比较,肯定不太公平。
在全部六种基准中,训练基准[MLPerf Training]和推理(数据中心)基准[MLPerf Inf]最为流行,提交这两类基准测试结果的系统和芯片也最多。其中在训练基准6个版本(v0.5,v0.6,v0.7,v1.0,v1.1和v2.0)下共有440多个性能结果,提交者包括微软Azure、百度、戴尔、富士通、谷歌、Graphcore、HPE、浪潮、Habana、联想、NVIDIA和三星等大厂和明星初创公司。而推理(数据中心)基准的六个版本(v0.5,v0.7,v1.0,v1.1,v2.0和v2.1)目前共收集了560多个性能结果,明显多于训练基准的结果。这主要是因为训练芯片的设计门槛更高,除了Graphcore外,很少有初创AI芯片公司涉及到训练任务,而在推理(数据中心)基准测试结果的榜单上可以看到更多初创公司的身影。
下表列出了训练基准和推理(数据中心)基准包含的任务,以及所使用的数据集和模型。
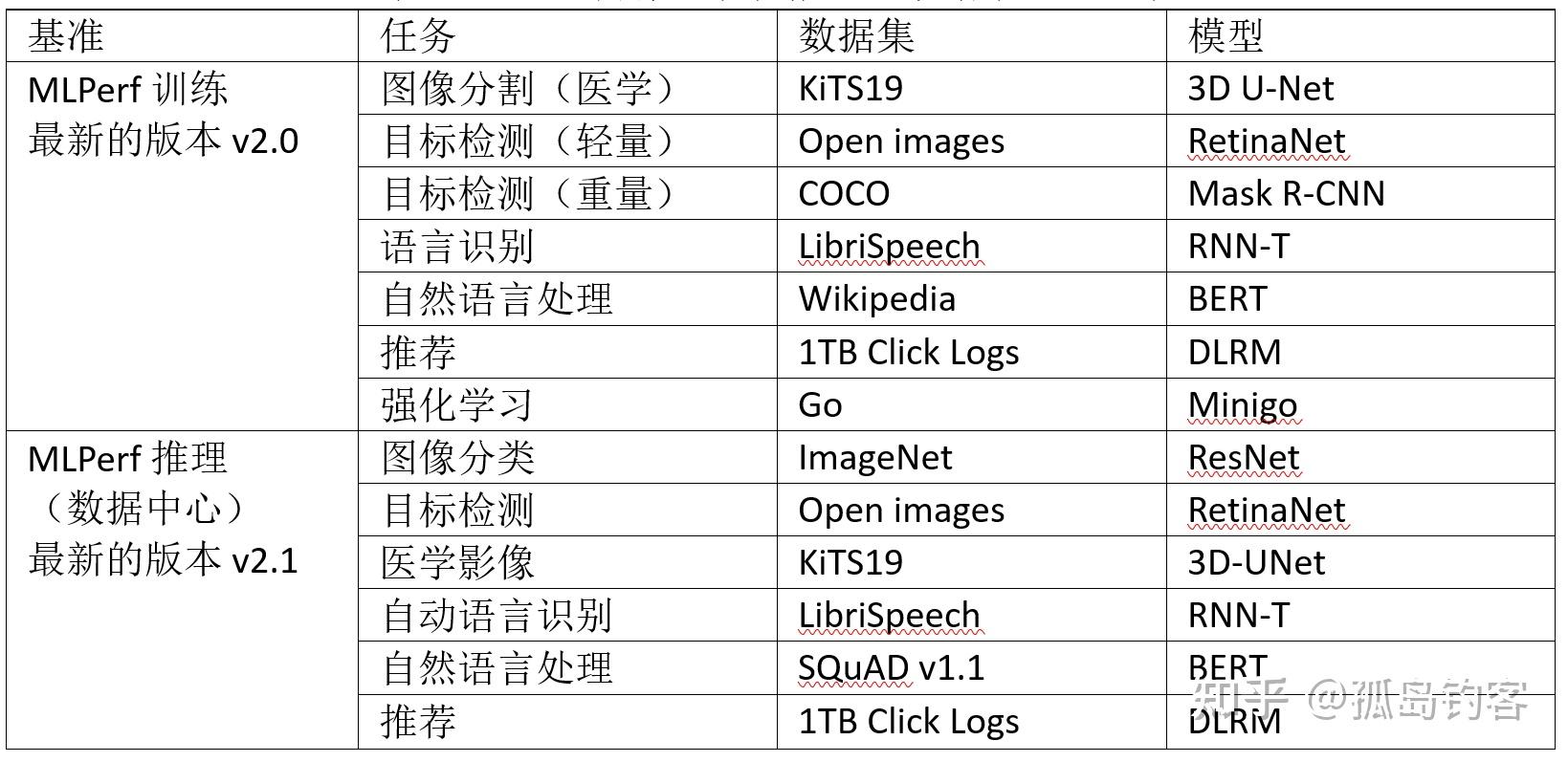
MLPerf训练基准和推理(数据中心)基准
其他的四项基准目前提交测试结果并不多,其中训练HPC基准[MLPerf HPC]是专门为科学领域高性能(High Performance Computing)系统开发的,专注于人工智能在科研领域如天体物理学和气象学的应用,参与评估的HPC系统包括在2020年取得世界超算第一的富岳(Fugaku)。而推理(边缘侧)基准的任务除了没有推荐任务外,其他的任务和数据中心基准一样。推理(移动设备)基准[MLPerf Mobile]则面向手机系统,包括三星手机和基于高通芯片的OPPO手机提交了测试结果。最后推理(Tiny)基准[MLPerf Tiny]则针对基于微控制器(Microcontroller Unit,MCU)的嵌入式系统平台,目前参与测试的基本是基于RISC-V和ARM Cortex M 系列的系统。任务方面则是不需要太多算力的应用,诸如视觉唤醒词(Visual Wake Words),关键词检测 (Keyword spotting)异常检测(Anomaly Detection)。
由于各个标准的任务不完全一样,因此衡量的标准和侧重点也不尽相同。比如两种训练基准的评判标准是用多少分钟能够完成相应的任务;而数据中心推理则关注于在线情况下的每秒查询数以及离线情况下的每秒样本数。针对边缘侧应用对实时的需求,边缘侧的推理更注重实时情况下任务的时延是多少毫秒。移动设备的推理基准除了毫米级的时延外,还考虑每秒帧数或样本数。由于嵌入式系统对功耗有着极致的要求,推理(Tiny) 基准在衡量毫米级时延的同时,也看重完成任务消耗了多少微焦耳(uJ)的能量。
近年以来,国产AI芯片不断在MLPerf上刷榜,比如2019年11月,阿里巴巴的含光800人工智能加速芯片在图像分类任务的Resnet50 v1.5基准测试中,在四个场景都取得了单芯片第一的成绩。2022年9月,壁仞科技的通用GPU芯片BR104,拿下数据中心推理评测中自然语言处理(BERT模型)和图像分类(ResNet50模型)两类基准评测 “available” (可售产品类别)单卡性能全球第一的成绩,更是在BERT模型下达到了英伟达目前主流GPU A100单卡性能的1. 58倍。还是在2022年9月,墨芯人工智能的S30计算卡以95784 FPS的单卡算力,夺得Resnet-50模型算力全球第一,甚至超过了英伟达于2022年发布的最新GPU H100。真心希望在以后的MLPerf榜单上可以看到更多中国芯靓丽的身影。
[Accelergy] Wu Y N, Emer J S, Sze V., “Accelergy: An Architecture- Level Energy Estimation Methodology for Accelerator Designs” 2019 IEEE/ ACM International Conference on Computer- Aided Design, Westminster, CO, USA, 2019.
[Timeloop] Parashar A, et al. “Timeloop: A Systematic Approach to DNN Accelerator Evaluation”, IEEE International Symposium on Performance Analysis of Systems and Software, Madison, WI, USA, 2019.
[MLPerf] Mattson, Peter, et al. "MLPerf: An industry standard benchmark suite for machine learning performance." IEEE Micro 40.2 (2020): 8-16.
[MLPerf HPC] Steven Farrell etc., “MLPerf HPC: A Holistic Benchmark Suite for Scientific Machine Learning on HPC Systems”, arXiv, 2021, https://arxiv.org/abs/2110.11466
[MLPerf Inf] Reddi, Vijay Janapa, et al. "Mlperf inference benchmark." 2020 ACM/IEEE 47th Annual International Symposium on Computer Architecture (ISCA). IEEE, 2020.
[MLPerf Mobile] Reddi, Vijay Janapa, et al. "MLPerf mobile inference benchmark." arXiv preprint arXiv:2012.02328 (2020).
[MLPerf Tiny] Banbury, Colby, et al. "Mlperf tiny benchmark." arXiv preprint arXiv:2106.07597 (2021).
[MLPerf Training] Mattson, Peter, et al. "Mlperf training benchmark." Proceedings of Machine Learning and Systems 2 (2020): 336-349. |
|



 发表于 2023-1-17 21:37:17
发表于 2023-1-17 21:37:17