值得注意的是,上面这些示例图实在仅仅采用“a photo of Nahida”的时候所产生的样例图,所以看上去视觉效果较差。一旦合理地去调整prompt,Textual Inversion还是能够产出效果较为不错的图片的。同时,由于大部分Stable Diffusion的模型都是1.5版本的,其语义模型都采用的是CLIP模型,因此你在一个模型上训练好的语义向量往往可以无缝衔接到另外一个模型上。
二,DreamBooth
由于模型在训练过程中只需要保存一条语义向量就足够,因此Textual Inversion相对来说储存占用空间较小,一般十几KB就足够了。然而,这也带来了一个弊端,那就是Textual Inversion保存的信息有限,生成的角色的特征一般有点像,但又没那么像。同时,如果你要训练一些特定画风的模型,比如最近大火的真人模型chilloutmix,或者经典的二次元模型Anything V3,那这些画风层次上的控制就更不可能用几十kb的小小embedding来满足。
这就要提到另外一项技术DreamBooth了。这项技术的影响非常深远,几乎目前所有在市面上流通的模型都是采用DreamBooth炼制出来的Stable Diffusion V1.5的变种。同时,它的思想也并不复杂。对比起上面Textual Inversion一点模型的参数都不改,DreamBooth做的就极端很多了,它几乎改了整个模型的所有参数,因此训练出来的结果俨然就是个全新的Stable Diffusion 模型,大小都是一样大的,大概8G左右。(当然你也可以通过降低精度来缩小模型,比如改成fp16精度或者fp8精度。模型的大小就会缩小到1/2或者1/4)
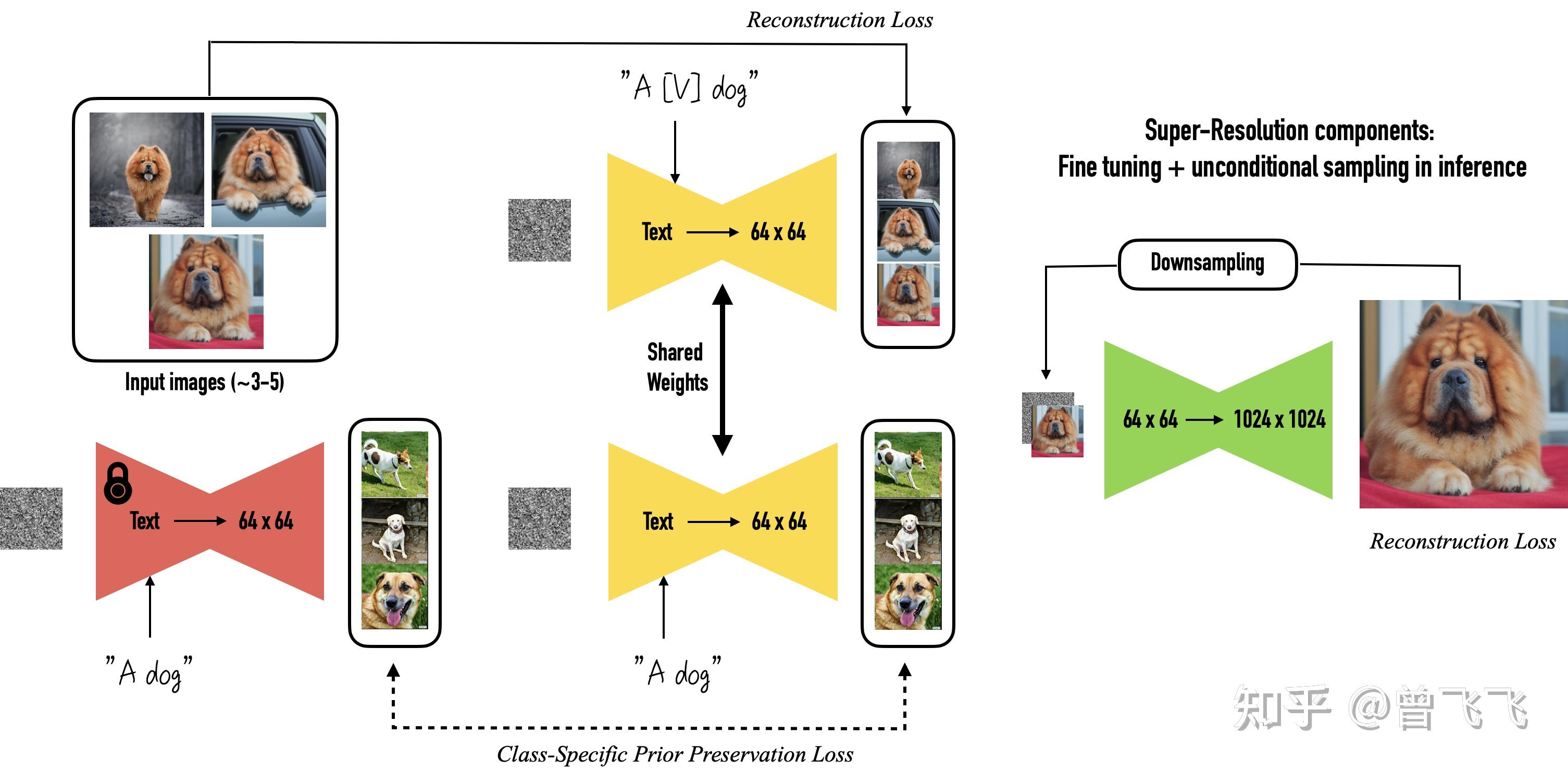
那具体来说DreamBooth是怎么改变Stable Diffusion 模型的参数的呢?整体来说也很简单,以下面的狗狗为例,同样我们先指定一个专有名词作给这个小狗,不过DreamBooth里面把它叫做 [V] 而不是上面的 S^* . 同时,这次你还需要给你想要生成的物体指定一个类别,比如说我们用 A\ dog 来指定“dog”作为专有名词[V]的类别。这样的话,我们最终的目标就是在输入“ A \ [V]\ dog ”的情况下,模型可以输出我们训练集中的那只小狗图片,就算成功了。
DreamBooth的想法是要保证两件事,第一是我们生成的结果要像这只狗,这也是最基本的要求,第二是要保证你原来的模型不能被这个新的finetune过程破坏,也就是说受训练的模型不应该在训练后忘记它原本有的知识和能力。
那么首先第一点,为了保证结果像我们给出的这只狗,我们只要输入“ A \ [V]\ dog ”然后去计算和原始图片集的Reconstruction Loss就好了。同时,因为DreamBooth里谷歌用的是他们自家的Imagen模型,所有里面是有超分辨率的模块的。为了保证细节上的一致性,谷歌就额外训练了他们的超分辨率模块,来确保模型能够恢复图像细节上的信息。
第二点,我们必须保证原来模型的知识不能在finetune的过程中被破坏,这是很重要的一点,也往往很容易被忽视。如果我对模型不加以约束,单纯用上面的Reconstruction Loss去训练,模型很容易就会过拟合到这只狗上。这样的话,就算我想要模型生成一只平平无奇的狗,模型可能也会丢给我一张训练用的狗狗图片。因此,dreambooth在训练之前,会先随机生成一些随机的狗的图片,一般50张左右,在训练的过程中用Prior Preservation Loss对模型加以约束,让模型不要跑的太偏。不加约束的话,就会出现下面实验中的情况。当我输入"A\ dog"而不是“ A \ [V]\ dog ”的时候,模型生成的图片却也都是训练集里柯基的样子(下图第二行),这明显就过拟合了。当我们加了Prior Preservation Loss之后,模型便不会过拟合,它就又能够生成平平无奇的普通狗狗了,就像图片最后一行中所展示的结果一样。



 发表于 2023-3-11 17:13:06
发表于 2023-3-11 17:13:06