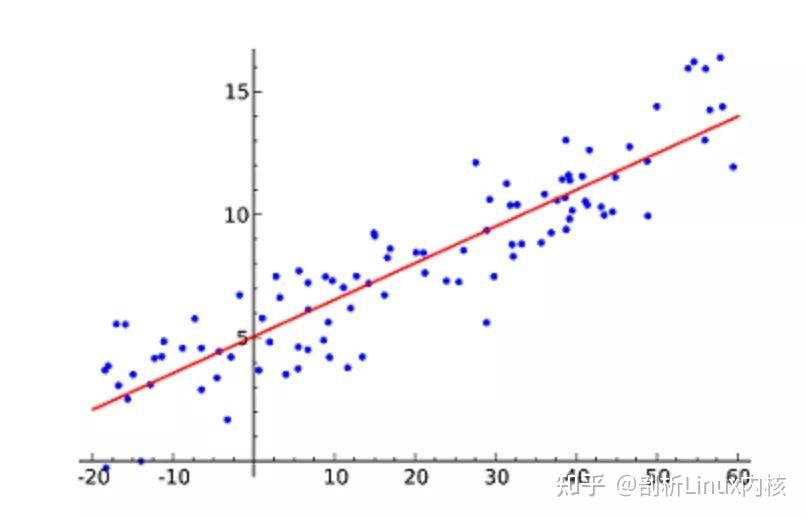
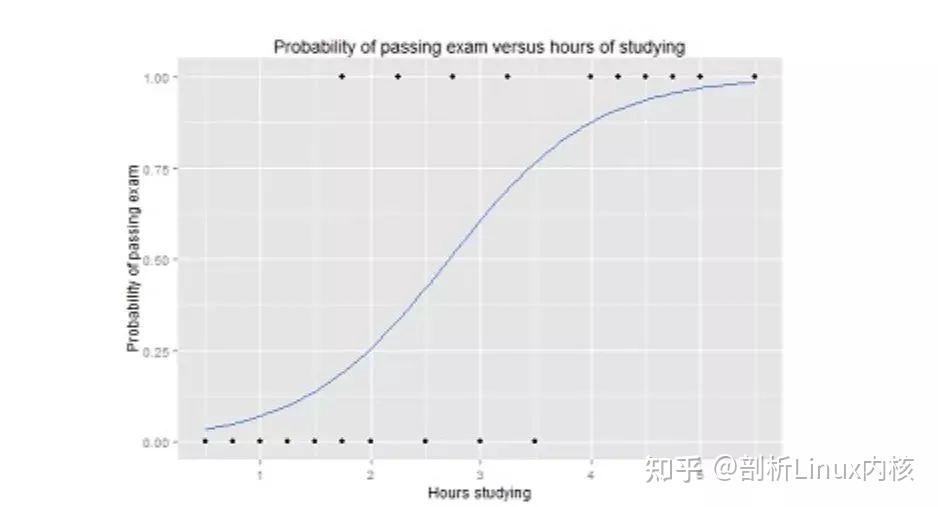
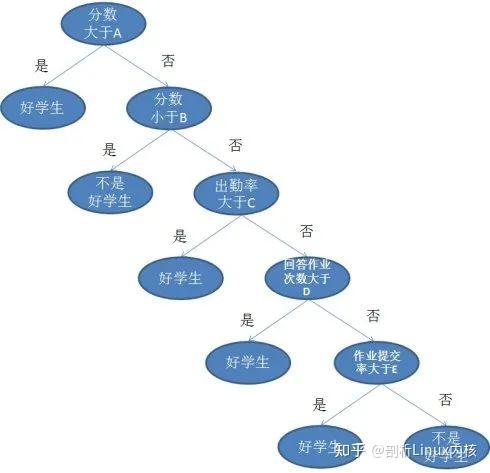
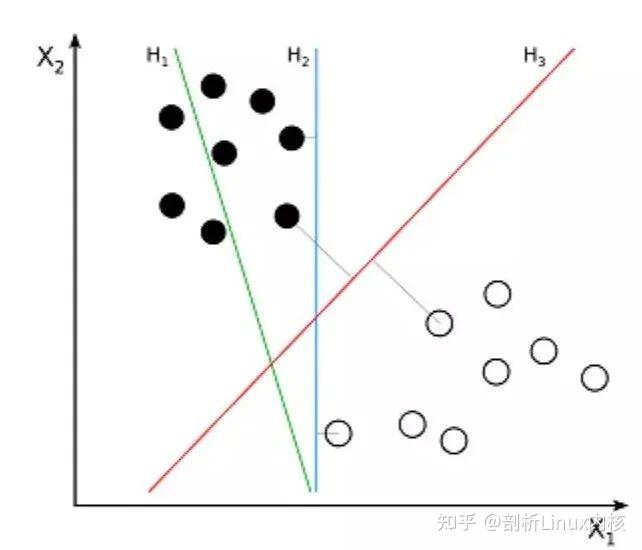
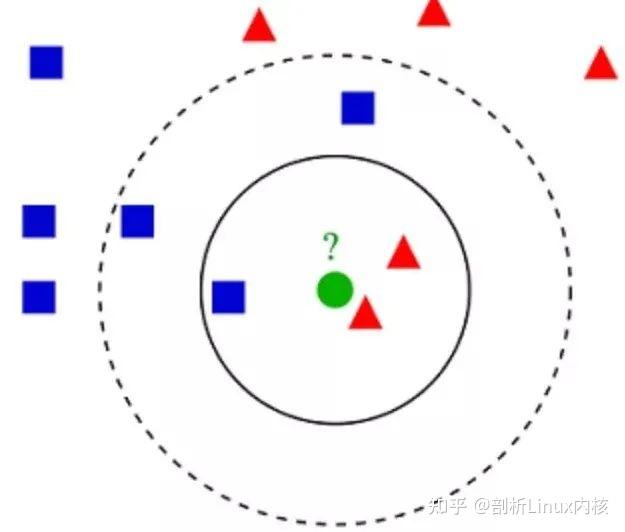
K- 最近邻算法(K-Nearest Neighbors,KNN)非常简单。KNN 通过在整个训练集中搜索 K 个最相似的实例,即 K 个邻居,并为所有这些 K 个实例分配一个公共输出变量,来对对象进行分类。
K 的选择很关键:较小的值可能会得到大量的噪声和不准确的结果,而较大的值是不可行的。它最常用于分类,但也适用于回归问题。
用于评估实例之间相似性的距离可以是欧几里得距离(Euclidean distance)、曼哈顿距离(Manhattan distance)或明氏距离(Minkowski distance)。欧几里得距离是两点之间的普通直线距离。它实际上是点坐标之差平方和的平方根。
KNN分类示例
KNN理论简单,容易实现,可用于文本分类、模式识别、聚类分析等。
七、K-均值
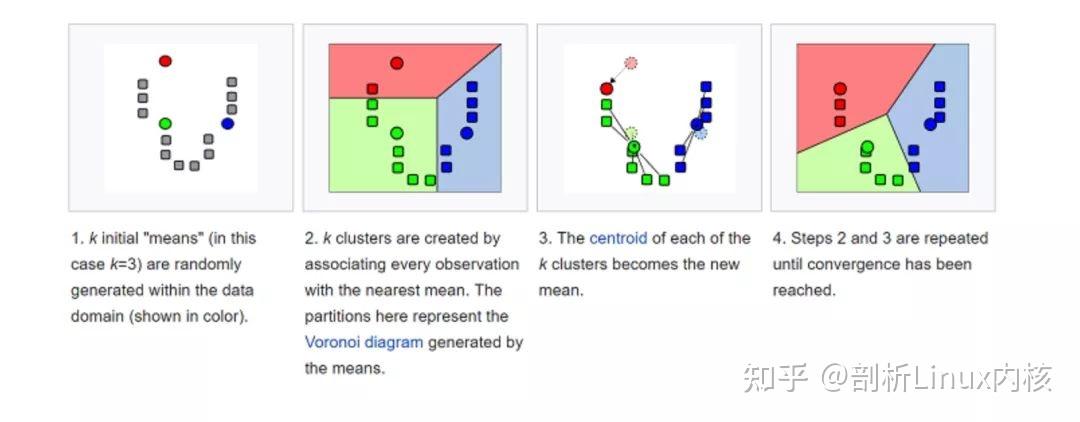
K-均值(K-means)是通过对数据集进行分类来聚类的。例如,这个算法可用于根据购买历史将用户分组。它在数据集中找到 K 个聚类。K- 均值用于无监督学习,因此,我们只需使用训练数据 X,以及我们想要识别的聚类数量 K。
该算法根据每个数据点的特征,将每个数据点迭代地分配给 K 个组中的一个组。它为每个 K- 聚类(称为质心)选择 K 个点。基于相似度,将新的数据点添加到具有最近质心的聚类中。这个过程一直持续到质心停止变化为止。



 发表于 2022-9-20 11:08:29
发表于 2022-9-20 11:08:29