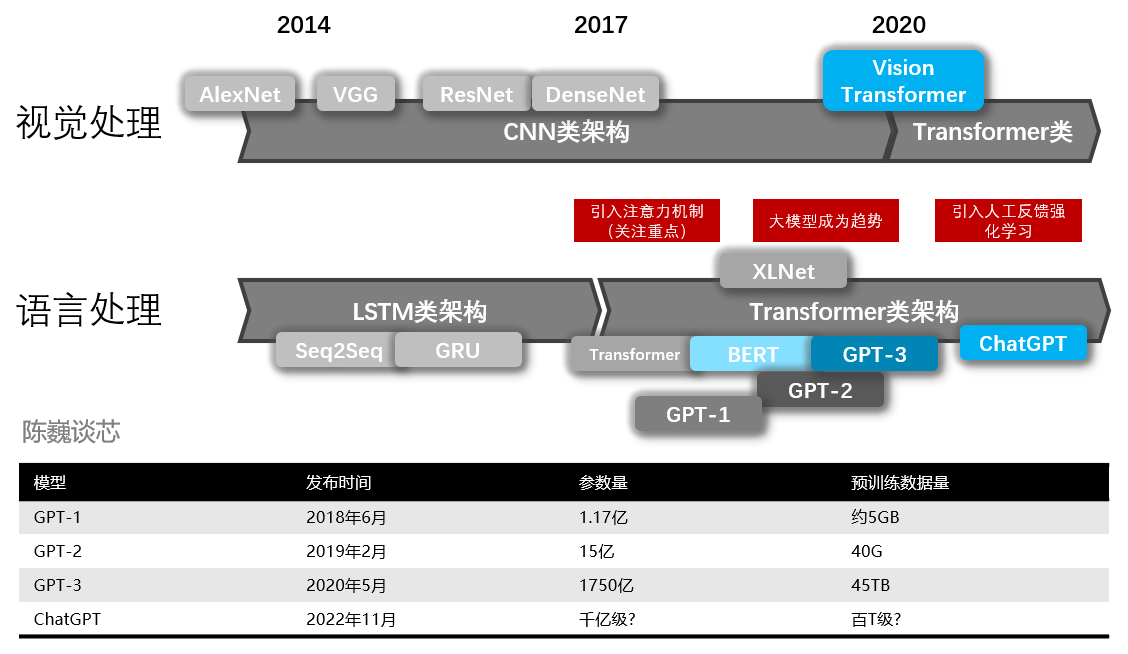
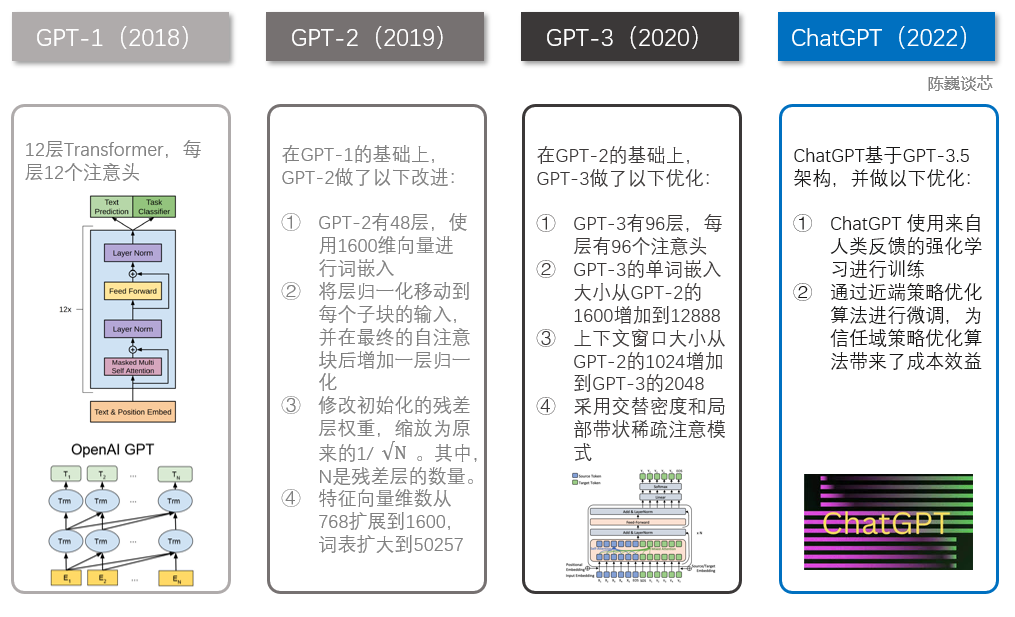
ChatGPT与GPT 1-3的技术对比
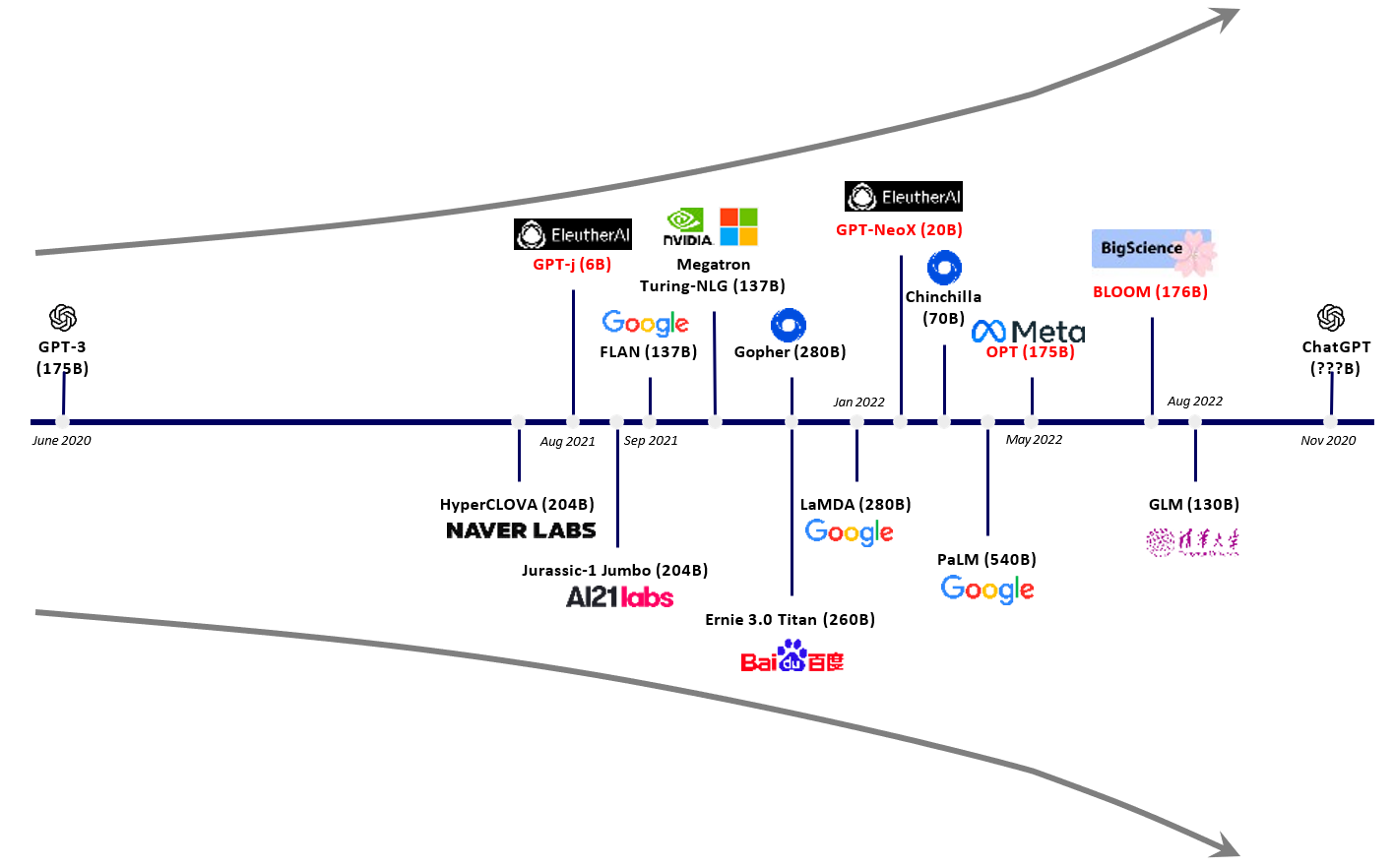
GPT家族与BERT模型都是知名的NLP模型,都基于Transformer技术。GPT-1只有12个Transformer层,而到了GPT-3,则增加到96层。
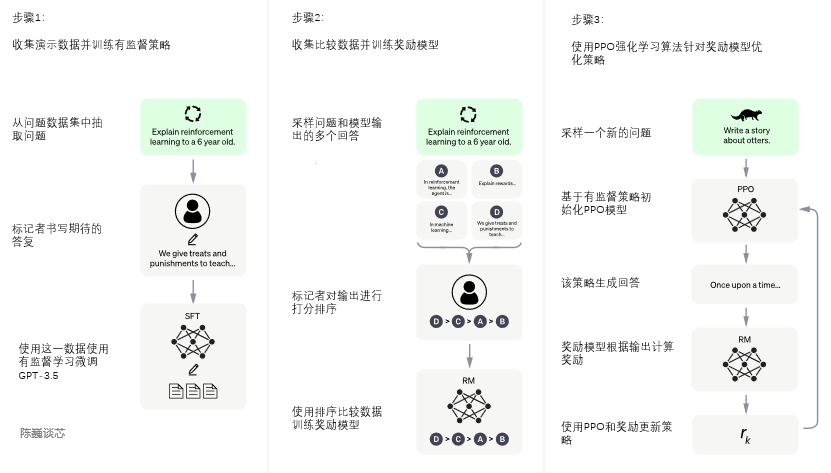
ChatGPT 与GPT-3.5的主要区别在于,新加入了被称为RLHF(Reinforcement
Learning from Human Feedback,人类反馈强化学习)。这一训练范式增强了人类对模型输出结果的调节,并且对结果进行了更具理解性的排序。
在InstructGPT中,以下是“goodness of sentences”的评价标准。
真实性:是虚假信息还是误导性信息?
无害性:它是否对人或环境造成身体或精神上的伤害?
有用性:它是否解决了用户的任务?
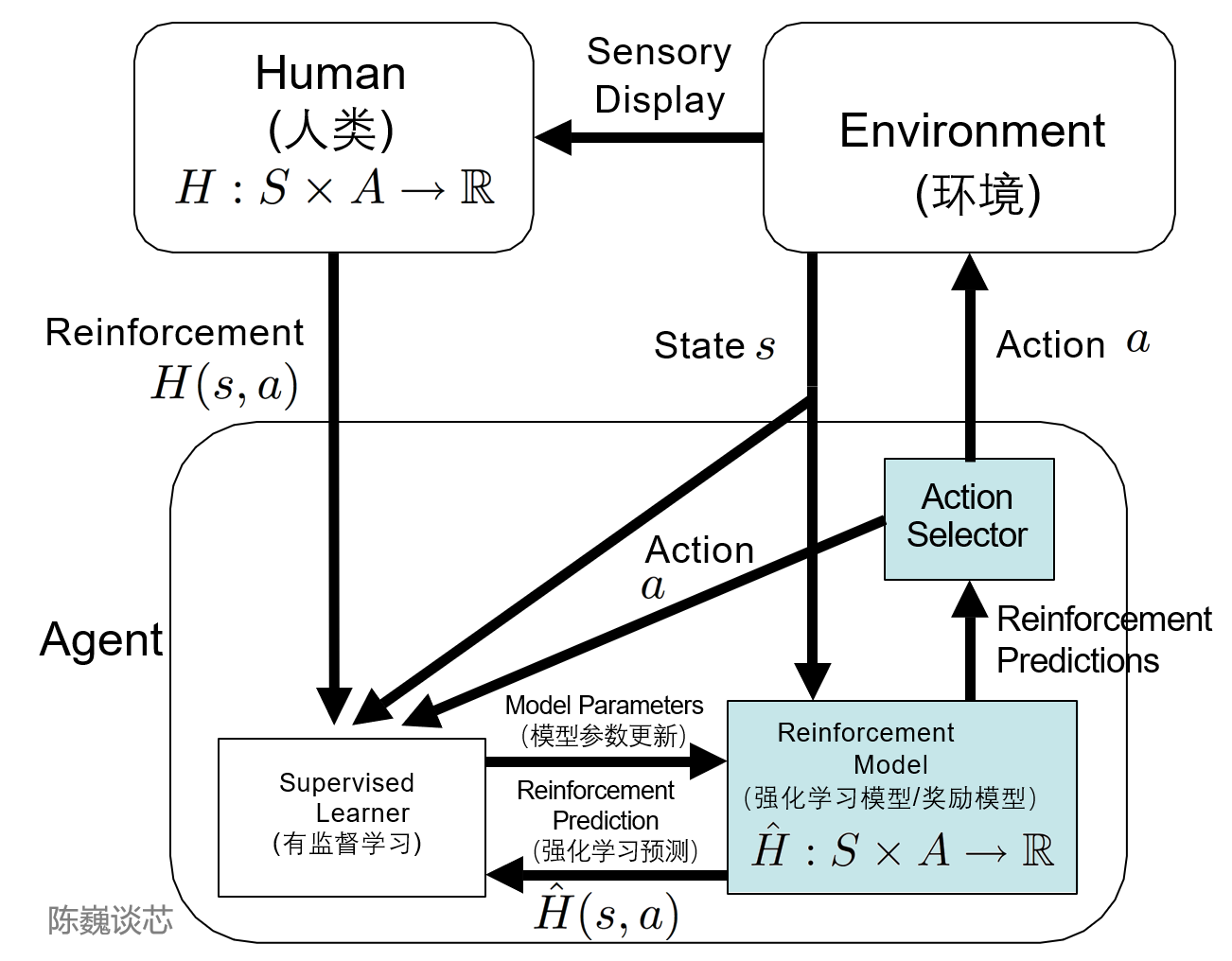
这里不得不提到TAMER(Training an Agent Manually via Evaluative Reinforcement,评估式强化人工训练代理)这个框架。该框架将人类标记者引入到Agents的学习循环中,可以通过人类向Agents提供奖励反馈(即指导Agents进行训练),从而快速达到训练任务目标。



 发表于 2023-1-12 10:56:31
发表于 2023-1-12 10:56:31